

Excel VBAのコーディング事例をご紹介しています。
事例iにするテーマを決めて、その機能を実現するためのコーディングを動く形でお示していますが、今回は前回に引き続き「Excel VBAでバイナリーエディタを作る」をテーマといたします。
※前回は「SHIFT-JIS編」、今回は「UTF-8編」になります。
「バイナリーエディタを作る」ためのコーディング自体はほぼほぼ同じなのですが、それぞれのコード体系の違いを実装する部分が大きく異なるので、分けざるを得ない認識です。
コーディング自体は「構造化・標準化は考慮しつつも極力コーディング量は減らし、その上で可読性を維持する」という思いは持ちつつも「テーマに沿って動くことを優先して実装」しています。
※動作は32bit版Excel 2016と64bit版Excel 2021の バージョン2304(ビルド 16327.20248)を使用して検証しています。
Excel VBAで実装するにあたり文字コードがUTF-8の場合の考慮点
前回、「バイナリーエディタとは」及び「Excel VBAで実装するための考慮点」につきましては、ご説明をいたしましたので、今回は文字コードがUTF-8の場合に必要になる考慮点について記述して参ります。
そのため、前回記述しました内容は「Excel VBAでバイナリーエディタを作る(SHIFT-JIS編)」をご参照いただければ幸いです。
なおメインサブルーチンは次の2つになります。
- ァイルを選択してバイナリ配列に読み込み「16進表記」と「指定された文字コードに変換した表記(以下 UTF-8表記)」をセットするサブルーチン
- セルにセットされた文字にフォーカスが当たると、「16進表記」と「UTF-8表記」それぞれでの該当する場所に印を付けるサブルーチン
それぞれ順を追ってご説明いたします。
1.ファイルをバイナリ配列に読み込み「16進」と「UTF-8」で表記する
このサブルーチンで文字コードがUTF-8の場合の考慮点は次のようになります。
- UTF-8表記はユーザ関数で文字コード変換をします。
- Shift-JIS表記ではChr関数で文字コード変換をしていますが、UTF-8にはそのような組み込み関数は用意されていません。そこでADO(ActiveX Data Objects)のStreamオブジェクトを使用したユーザ関数「AdoStrmConv」を使用します。
- このユーザ関数の詳細、及びコーティング事例は別の回になりますが「Excel VBAで文字コード表を作る(SHIFT-JIS編)」でご説明いたしますので、そちらをご参照いただければ幸いです。
以下UTF-8表記で文字コードの長さに応じて「どのように横16列のセルに文字をセットするか?」の説明になります。
- U2バイト文字では1カラム目に2バイト文字をセットし、2カラム目は空文字をセットします。
- 2バイト文字の判定はつぎのようしています。
- 「0xDF≧1バイト目≧0xC2」でかつ「0xBF≧2バイト目≧0x80」
- 16文字目が2バイト文字になった時は、次の行のUTF-8表記の1文字目は空文字をセットします。
- 2バイト文字の判定はつぎのようしています。
- 3バイト文字では1カラム目に3バイト文字をセットし、2~3カラム目は空文字をセットします。
- 3バイト文字の判定は次のようにしています。
- 「0xEF≧1バイト目≧0xE0」でかつ「0xBF≧2バイト目と3バイト目≧0x80」
- 15文字目が3バイト文字になった時は、次の行のUTF-8表記の1文字目は空文字をセットします。
- 16文字目が3バイト文字になった時は、次の行のUTF-8表記の1~2文字目は空文字をセットします。
- 3バイト文字の判定は次のようにしています。
- 4バイト文字では1カラム目に4バイト文字をセットし、2~4カラム目は空文字をセットします。
- 4バイト文字の判定は次のようにしています。
- 「1バイト目=0xF0 or 0xF3 or 0xF4」でかつ「0xBF≧2バイト目と3バイト目と4バイト目≧0x80」
- 14文字目が4バイト文字になった時は、次の行のUTF-8表記の1文字目は空文字をセットします。
- 15文字目が4バイト文字になった時は、次の行のUTF-8表記の1~2文字目は空文字をセットします。
- 16文字目が4バイト文字になった時は、次の行のUTF-8表記の1~3文字目は空文字をセットします。
- 4バイト文字の判定は次のようにしています。
2.「16進表記」と「UFT-8表記」それぞれでの該当する場所に印を付ける
雛形シートを作成し、そのシートのWorksheetオブジェクトのSelectionChangeイベントに、標準モジュールに記述した本サブルーチンを呼び出すコーディングしますが、このサブルーチンでの文字コードがUTF-8の場合の考慮点は次のようになります。
- 文字コードの長さが「2~4バイト文字か?」の判定は「16進表記」のデータを見て行います。
- 判定条件は前章「1.」に記載しました内容になります。
- 「16進表記」と「UTF-8表記」ともにセルが選択された時の背景色の設定は、前章「1.」で文字をセットしたセルに対して行います。
- 「選択されたセルが位置」と「文字コードの長さ(2バイト文字から4バイト文字)」での場合分けが必要になり、そのためどうしてもコーディング量が増えてしまいます。
そこで2バイト文字から4バイト文字それぞれにコーディング量を削減するための子サブルーチンを作っていますのであらかじめお含み置きください。 - 上記の子サブルーチンではRangeオブジェクトのOffsetプロパティを使用して、「16進表記」と「UTF-8表記」のそれぞれ位置を指定します。
またそれぞれのセルを指定する時の計算には下記のような規則性があるので、それを利用してコーディング量を少なくしています。- カレント行の、行のOffsetのは0、次の行では1になります。
- 「16進表記」から「UTF-8表記」に移る時
- カレント行では行のOffsetに+16、
行替わりした時は-16にします。
- カレント行では行のOffsetに+16、
- 「UTF-8表記」から「16進表記」に移る時
- カレント行では行のOffsetに-16、
行替わりした時は-32にします。
- カレント行では行のOffsetに-16、
- 「選択されたセルが位置」と「文字コードの長さ(2バイト文字から4バイト文字)」での場合分けが必要になり、そのためどうしてもコーディング量が増えてしまいます。
実際のコーティング事例
実行するためには、ここで掲載しているコーディング事例以外に次のコーディング事例も必要になりますのでご注意ください。
- 「Excel VBAで文字コード表を作る(SHIFT-JIS編)」に掲載した次のユーザ関数
- AdoStrmConv ←UTF-8に文字コード変換するために必要
- 「Excel VBAでバイナリーエディタを作る(SHIFT-JIS編)」に掲載した次のコーティング事例
- BinaryEditorWrite と WriteFileBianary ←ファイルを書込む場合に必要
- ReadFileBianary ←ファイルを読み込み時に必要
まずは「UTF8雛形」というシート名でシートを作成して、そのシートのWorksheetオブジェクトのSelectionChangeイベントに次のようなコーディングをします。
Private Sub Worksheet_SelectionChange(ByVal Target As Range)
Call BianaryEditorSkinUtf8(Target)
End Sub
上記を呼び出している「BianaryEditorSkinUtf8」は、標準モジュールで次のようにコーディングします。
Public Sub BianaryEditorSkinUtf8(rTarget As Range)
Application.ScreenUpdating = False '画面固定
If rTarget.CountLarge > 1 Then Exit Sub '複数セル選択はスルー
Columns("B:AG").Interior.ColorIndex = 0 ' 対象列の背景色をクリア
With rTarget
If .Column >= 2 And .Column <= 14 Then '16進表記の列範囲 1~13番目
.Interior.ColorIndex = 20
.Offset(0, 16).Interior.ColorIndex = 20
If (.Value >= "C2" And .Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 0, 0, 16)
ElseIf (.Value >= "E0" And .Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 0, 0, 0, 0, 16, 16)
ElseIf .Value = "F0" Or .Value = "F3" Or .Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 0, 0, 0, 0, 0, 0, 16, 16, 16)
End If
ElseIf .Column = 15 Then '16進表記の列範囲 14番目
.Interior.ColorIndex = 20
.Offset(0, 16).Interior.ColorIndex = 20
If (.Value >= "C2" And .Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 0, 0, 16)
ElseIf (.Value >= "E0" And .Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 0, 0, 0, 0, 16, 16)
ElseIf .Value = "F0" Or .Value = "F3" Or .Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 0, 0, 1, 0, 0, -16, 16, 16, 0)
End If
ElseIf .Column = 16 Then '16進表記の列範囲 15番目
.Interior.ColorIndex = 20
.Offset(0, 16).Interior.ColorIndex = 20
If (.Value >= "C2" And .Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 0, 0, 16)
ElseIf (.Value >= "E0" And .Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 0, 1, 0, -16, 16, 0)
ElseIf .Value = "F0" Or .Value = "F3" Or .Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 0, 1, 1, 0, -16, -16, 16, 0, 0)
End If
ElseIf .Column = 17 Then '16進表記の列範囲 16番目
.Interior.ColorIndex = 20
.Offset(0, 16).Interior.ColorIndex = 20
If (.Value >= "C2" And .Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 1, -16, 0)
ElseIf (.Value >= "E0" And .Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 1, 1, -16, -16, 0, 0)
ElseIf .Value = "F0" Or .Value = "F3" Or .Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 1, 1, 1, -16, -16, -16, 0, 0, 0)
End If
ElseIf (.Column >= 18 And .Column <= 30) Then 'UTF8表記の列範囲 1~13番目
.Interior.ColorIndex = 20
.Offset(0, -16).Interior.ColorIndex = 20
If (.Offset(0, -16).Value >= "C2" And .Offset(0, -16).Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 0, -16, 0)
ElseIf (.Offset(0, -16).Value >= "E0" And .Offset(0, -16).Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 0, 0, -16, -16, 0, 0)
ElseIf .Offset(0, -16).Value = "F0" Or .Offset(0, -16).Value = "F3" Or .Offset(0, -16).Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 0, 0, 0, -16, -16, -16, 0, 0, 0)
End If
ElseIf .Column = 31 Then 'UTF8表記の列範囲 14番目
.Interior.ColorIndex = 20
.Offset(0, -16).Interior.ColorIndex = 20
If (.Offset(0, -16).Value >= "C2" And .Offset(0, -16).Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 0, -16, 0)
ElseIf (.Offset(0, -16).Value >= "E0" And .Offset(0, -16).Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 0, 0, -16, -16, 0, 0)
ElseIf .Offset(0, -16).Value = "F0" Or .Offset(0, -16).Value = "F3" Or .Offset(0, -16).Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 0, 0, 1, -16, -16, -32, 0, 0, -16)
End If
ElseIf .Column = 32 Then 'UTF8表記の列範囲 15番目
.Interior.ColorIndex = 20
.Offset(0, -16).Interior.ColorIndex = 20
If (.Offset(0, -16).Value >= "C2" And .Offset(0, -16).Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 0, -16, 0)
ElseIf (.Offset(0, -16).Value >= "E0" And .Offset(0, -16).Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 0, 1, -16, -32, 0, -16)
ElseIf .Offset(0, -16).Value = "F0" Or .Offset(0, -16).Value = "F3" Or .Offset(0, -16).Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 0, 1, 1, -16, -32, -32, 0, -16, -16)
End If
ElseIf .Column = 33 Then 'UTF8表記の列範囲 16番目
.Interior.ColorIndex = 20
.Offset(0, -16).Interior.ColorIndex = 20
If (.Offset(0, -16).Value >= "C2" And .Offset(0, -16).Value <= "DF") Then '2バイト文字の1バイト目
Call SkinUtf8_2(rTarget, 1, -32, -16)
ElseIf (.Offset(0, -16).Value >= "E0" And .Offset(0, -16).Value <= "EF") Then '3バイト文字の1バイト目
Call SkinUtf8_3(rTarget, 1, 1, -32, -32, -16, -16)
ElseIf .Offset(0, -16).Value = "F0" Or .Offset(0, -16).Value = "F3" Or .Offset(0, -16).Value = "F4" Then '4バイト文字の1バイト目
Call SkinUtf8_4(rTarget, 1, 1, 1, -32, -32, -32, -16, -16, -16)
End If
End If
End With
Application.ScreenUpdating = True '画面固定解除
End Sub
なお上記コーディング事例にはコーディンクを簡素化するための子サブルーチンが2バイト文字から4バイト文字まで3つ存在しますので、続けてご紹介いたします。
Private Sub SkinUtf8_2(rTarget As Range, lrow1 As Long, lcolhex1 As Long, lcolchr1 As Long)
With rTarget
If (.Offset(lrow1, 1 + lcolhex1).Value >= "80" And .Offset(lrow1, 1 + lcolhex1).Value <= "BF") Then '2バイト文字の2バイト目
.Offset(lrow1, 1 + lcolhex1).Interior.ColorIndex = 20
.Offset(lrow1, 1 + lcolchr1).Interior.ColorIndex = 20
End If
End With
End Sub
Private Sub SkinUtf8_3(rTarget As Range, lrow1 As Long, lrow2 As Long, lcolhex1 As Long, lcolhex2 As Long, lcolchr1 As Long, lcolchr2 As Long)
With rTarget
If (.Offset(lrow1, 1 + lcolhex1).Value >= "80" And .Offset(lrow1, 1 + lcolhex1).Value <= "BF") And _
(.Offset(lrow2, 2 + lcolhex2).Value >= "80" And .Offset(lrow2, 2 + lcolhex2).Value <= "BF") Then '3バイト文字の2~3バイト目
.Offset(lrow1, 1 + lcolhex1).Interior.ColorIndex = 20
.Offset(lrow2, 2 + lcolhex2).Interior.ColorIndex = 20
.Offset(lrow1, 1 + lcolchr1).Interior.ColorIndex = 20
.Offset(lrow2, 2 + lcolchr2).Interior.ColorIndex = 20
End If
End With
End Sub
Private Sub SkinUtf8_4(rTarget As Range, lrow1 As Long, lrow2 As Long, lrow3 As Long, lcolhex1 As Long, lcolhex2 As Long, lcolhex3 As Long, _
lcolchr1 As Long, lcolchr2 As Long, lcolchr3 As Long)
With rTarget
If (.Offset(lrow1, 1 + lcolhex1).Value >= "80" And .Offset(lrow1, 1 + lcolhex1).Value <= "BF") And _
(.Offset(lrow2, 2 + lcolhex2).Value >= "80" And .Offset(lrow2, 2 + lcolhex2).Value <= "BF") And _
(.Offset(lrow3, 3 + lcolhex3).Value >= "80" And .Offset(lrow3, 3 + lcolhex3).Value <= "BF") Then '4バイト文字の2~4バイト目
.Offset(lrow1, 1 + lcolhex1).Interior.ColorIndex = 20
.Offset(lrow2, 2 + lcolhex2).Interior.ColorIndex = 20
.Offset(lrow3, 3 + lcolhex3).Interior.ColorIndex = 20
.Offset(lrow1, 1 + lcolchr1).Interior.ColorIndex = 20
.Offset(lrow2, 2 + lcolchr2).Interior.ColorIndex = 20
.Offset(lrow3, 3 + lcolchr3).Interior.ColorIndex = 20
End If
End With
End Sub
最後に今回のメインサブルーチンとなる「ファイルをバイナリーエディタ―に読み込む処理」のコーディング事例になります。
このコーディングでパラメータとして使用しているコンスタント変数を先にご説明いたします。
- 15行目のコンスタント変数「HINAGATA」に雛形シート名をセットします。
- 下記では「SJIS雛形」をセットしています。
- 16行目のコンスタント変数「stDEFAULT」にはファイルを開く際のデフォルトパスをセットします。
- 下記では「C:\Users」をセットしています。
Sub BinaryEditorReadUtf8()
Dim st_FilePathName As String 'バイナリファイルパスとファイル名
Dim st_FileName As String
Dim fn As Integer 'ファイル番号
Dim by_Ary() As Byte '読み込みデータ配列
Dim l_Size As Long 'ファイルサイズ
Dim l As Long, i As Integer
Dim l_row As Long, l_col As Long
Dim st_Hex As String, st_Hex1 As String, st_Hex2 As String, st_Hex3 As String, st_Byte As String
Dim by_buf() As Byte
Dim st_tsv As String, st_tsv1 As String, st_tsv2 As String
Dim i_flg(2 To 4) As Integer
Const stMOJICD As String = "UTF-8"
'-------------------------------------------------------------------
Const HINAGATA As String = "UTF8雛形" 'ひな形シート名を設定
Const stDEFAULT As String = "C:\Users" '必要がある時にパスのデフォルト設定をします
Dim dbl_t As Double
'バイナリファイルパスとファイル名の設定・取得
st_FilePathName = stDEFAULT
If Len(chooseFolder(st_FilePathName)) = 0 Then
MsgBox "ファイルが選択されていません。"
Exit Sub '<<<<<<<<
End If
'
l_Size = ReadFileBianary(st_FilePathName, by_Ary)
If l_Size = 0 Then
MsgBox "ファイルを読み込めませんでしたん。"
Exit Sub '<<<<<<<<
End If
'
dbl_t = Timer
st_FileName = Mid(st_FilePathName, InStrRev(st_FilePathName, Chr(92)) + 1) 'フルパスからファイル名取得
Application.ScreenUpdating = False '画面固定
Worksheets(HINAGATA).Copy after:=Sheets(Sheets.Count) 'ひな形シートをコピー
With ActiveSheet
.Name = st_FileName 'シート名をファイル名に変更
'初期設定
l = 0 'バイナリ配列の添え字をリセット
l_row = 1: l_col = 0 '行番号:列番号をリセット
st_tsv = "": st_tsv1 = "": st_tsv2 = "" '1行を書き出す変数:16進コード書出し変数:utf8表示書出し変数
i_flg(2) = 0 '16文字目が2バイトコードだったかをハンドリング
i_flg(3) = 0 '15~16文字目が3バイトコードだったかをハンドリング
i_flg(4) = 0 '14~16文字目が4バイトコードだったかをハンドリング
Do
st_Hex = Right("00" & Hex(by_Ary(l)), 2) 'バイナリ配列の文字を一個づつHex関数で処理
l_col = l_col + 1
st_tsv1 = st_tsv1 & st_Hex & vbTab '文字コード書出し変数に1行16列をタブ区切りでまとめて設定
If i_flg(2) = 1 Then '前行の16文字目が2バイト文字の1バイト目
st_Byte = """" & " " & """" 'ダブルクォーテーションで囲った1スペースをセット
i_flg(2) = 0 'フラグをリセット
ElseIf i_flg(3) = 1 Then '前行の15文字目が3バイト文字の1バイト目
st_Byte = """" & " " & """" '〃1スペースをセット
i_flg(3) = 0 'フラグをリセット
ElseIf i_flg(3) = 2 Then '前行の16文字目が3バイト文字の1バイト目
st_Byte = """" & " " & """" '〃1スペースをセット
i_flg(3) = 1 '減数値をセット
ElseIf i_flg(4) = 1 Then '前行の14文字目が4バイト文字の1バイト目
st_Byte = """" & " " & """" '〃1スペースをセット
i_flg(4) = 0 'フラグをリセット
ElseIf i_flg(4) = 2 Then '前行の15文字目が4バイト文字の1バイト目
st_Byte = """" & " " & """" '〃1スペースをセット
i_flg(4) = 1 '減数値をセット
ElseIf i_flg(4) = 3 Then '前行の16文字目が4バイト文字の1バイト目
st_Byte = """" & " " & """" '〃1スペースをセット
i_flg(4) = 2 '減数値をセット
ElseIf st_Hex <= "1F" Then '文字がセットされていない文字コード域
st_Byte = """" & "." & """"
ElseIf (st_Hex >= "C2" And st_Hex <= "DF") Then '2バイト文字の1バイト目
ReDim by_buf(1)
If l >= l_Size - 1 Then 'バイナリ配列の終端の時は次の文字コードが無いのでピリオドに
st_Byte = """" & "." & """" 'ダブルクォーテーションで囲ったピリオドをセット
Else
st_Hex1 = Right("00" & Hex(by_Ary(l + 1)), 2) 'バイナリ配列の次の文字を取得
If (st_Hex1 >= "80" And st_Hex1 <= "BF") Then '2バイト文字の2バイト目
by_buf(0) = by_Ary(l)
by_buf(1) = by_Ary(l + 1)
st_Byte = """" & AdoStrmConv(by_buf, stMOJICD) & """" 'ユーザ関数でUtf-8 2バイト文字に変換
If l_col < 16 Then '16列のまとめに未到達
l_col = l_col + 1
st_tsv1 = st_tsv1 & st_Hex1 & vbTab
st_Byte = st_Byte & vbTab & """""" '2バイト文字の2バイト目はutf-8表示ではダブルクォーテーション×2の空文字
l = l + 1 '添え字のカウントアップ
Else
i_flg(2) = 1 '16列まとめの最後が2バイト文字だった事をフラグに設定
End If
Else '2バイト文字以外はピリオド
st_Byte = """" & "." & """"
End If
End If
ElseIf (st_Hex >= "E0" And st_Hex <= "EF") Then '3バイト文字の1バイト目
ReDim by_buf(2)
If l >= l_Size - 1 Then 'バイナリ配列の終端の時は次の文字コードが無いのでピリオドに
st_Byte = """" & "." & """"
Else
st_Hex1 = Right("00" & Hex(by_Ary(l + 1)), 2) 'バイナリ配列の次文字を取得
st_Hex2 = Right("00" & Hex(by_Ary(l + 2)), 2) 'バイナリ配列の次々文字を取得
If (st_Hex1 >= "80" And st_Hex1 <= "BF") And _
(st_Hex2 >= "80" And st_Hex2 <= "BF") Then '3バイト文字の2~3バイト目
by_buf(0) = by_Ary(l)
by_buf(1) = by_Ary(l + 1)
by_buf(2) = by_Ary(l + 2)
st_Byte = """" & AdoStrmConv(by_buf, stMOJICD) & """" 'ユーザ関数でUtf-8 3バイト文字に変換
If l_col < 15 Then '16列のまとめに未到達
l_col = l_col + 2
st_tsv1 = st_tsv1 & st_Hex1 & vbTab & st_Hex2 & vbTab
st_Byte = st_Byte & vbTab & """""" & vbTab & """""" '3バイト文字の2バイト目と3バイト目はutf-8表示では空文字
l = l + 2 '添え字のカウントアップ
ElseIf l_col = 15 Then '16列の15文字目の時
l_col = l_col + 1
st_tsv1 = st_tsv1 & st_Hex1 & vbTab
st_Byte = st_Byte & vbTab & """""" '3バイト文字の2バイト目はutf-8表示では空文字
l = l + 1 '添え字のカウントアップ
i_flg(3) = 1 '16列まとめの15文字目が3バイト文字だった事をフラグに設定
Else
i_flg(3) = 2 '16列まとめの16文字目が3バイト文字だった事をフラグに設定
End If
Else '3バイト文字以外はピリオド
st_Byte = """" & "." & """"
End If
End If
ElseIf st_Hex = "F0" Or st_Hex = "F3" Or st_Hex = "F4" Then '4バイト文字の1バイト目
ReDim by_buf(3)
If l >= l_Size - 1 Then 'バイナリ配列の終端の時は次の文字コードが無いのでピリオドに
st_Byte = """" & "." & """"
Else
st_Hex1 = Right("00" & Hex(by_Ary(l + 1)), 2) 'バイナリ配列の次文字を取得
st_Hex2 = Right("00" & Hex(by_Ary(l + 2)), 2) 'バイナリ配列の次々文字を取得
st_Hex3 = Right("00" & Hex(by_Ary(l + 3)), 2) 'バイナリ配列の次々々文字を取得
If (st_Hex1 >= "80" And st_Hex1 <= "BF") And _
(st_Hex2 >= "80" And st_Hex2 <= "BF") And _
(st_Hex3 >= "80" And st_Hex3 <= "BF") Then '4バイト文字の2~4バイト目
by_buf(0) = by_Ary(l)
by_buf(1) = by_Ary(l + 1)
by_buf(2) = by_Ary(l + 2)
by_buf(3) = by_Ary(l + 3)
st_Byte = """" & AdoStrmConv(by_buf, stMOJICD) & """" 'ユーザ関数でUtf-8 4バイト文字に変換
If l_col < 14 Then '16列のまとめに未到達
l_col = l_col + 3
st_tsv1 = st_tsv1 & st_Hex1 & vbTab & st_Hex2 & vbTab & st_Hex3 & vbTab
st_Byte = st_Byte & vbTab & """""" & vbTab & """""" & vbTab & """""" '4バイト文字の2バイト目から4バイト目はutf-8表示では空文字
l = l + 3 '添え字のカウントアップ
ElseIf l_col = 14 Then '16列の14文字目の時
l_col = l_col + 2
st_tsv1 = st_tsv1 & st_Hex1 & vbTab & st_Hex2 & vbTab
st_Byte = st_Byte & vbTab & """""" & vbTab & """""" '4バイト文字の2バイト目から3バイト目はutf-8表示では空文字
l = l + 2 '添え字のカウントアップ
i_flg(4) = 1 '16列まとめの14文字目が4バイト文字だった事をフラグに設定
ElseIf l_col = 15 Then '16列の15文字目の時
l_col = l_col + 1
st_tsv1 = st_tsv1 & st_Hex1 & vbTab
st_Byte = st_Byte & vbTab & """""" '4バイト文字の2バイト目はutf-8表示では空文字
l = l + 1 '添え字のカウントアップ
i_flg(4) = 2 '16列まとめの15文字目が4バイト文字だった事をフラグに設定
Else '16列の16文字目の時
i_flg(4) = 3 '16列まとめの16文字目が4バイト文字だった事をフラグに設定
End If
Else '4バイト文字以外はピリオド
st_Byte = """" & "." & """"
End If
End If
Else '1バイトの文字コード
If st_Hex >= "80" Then
st_Byte = """" & "." & """" '文字がセットされていない文字コードはピリオド
Else
ReDim by_buf(0)
by_buf(0) = by_Ary(l)
st_Byte = """" & AdoStrmConv(by_buf, stMOJICD) & """"
End If
End If
If st_Hex = "22" Then 'ダブルクォーテーション(")だったら
st_tsv2 = st_tsv2 & """""""""" & vbTab 'ダブルクォーテーション(")×2をダブルクォーテーションで括る
Else
st_tsv2 = st_tsv2 & st_Byte & vbTab 'utf-8書出し変数に1行16列をタブ区切りでまとめて設定
End If
If l_col >= 16 Then '列カウンタが16以上になっていたらセルにデータを出力
st_tsv = st_tsv & """" & Right("00000000" & Hex(l - 15), 8) & """" & vbTab '行番
st_tsv = st_tsv & st_tsv1 '最後はタブなので、そのままにする
st_tsv = st_tsv & Left(st_tsv2, Len(st_tsv2) - 1) 'utf-8書出し変数の行末のタブは除外
.Cells(l_row, 1).Value = st_tsv
l_col = 0: st_tsv = "": st_tsv1 = "": st_tsv2 = "" '各種変数の初期化
l_row = l_row + 1 '行番号をカウントアップ
End If
l = l + 1 '添え字のカウントアップ
If l > l_Size - 1 Then Exit Do 'ループエンド <<<<<<<<
Loop
If st_tsv1 <> "" Then '一番最後のデータを出力
st_tsv = st_tsv & """" & Right("00000000" & Hex(l - 15), 8) & """" & vbTab '行番
For i = l_col + 1 To 16 '1行に足りない分を付けたし
st_tsv1 = st_tsv1 & vbTab
st_tsv2 = st_tsv2 & """""" & vbTab 'ダブルクォーテーション(")×2で空文字
Next
st_tsv = st_tsv & st_tsv1
st_tsv = st_tsv & Left(st_tsv2, Len(st_tsv2) - 1) 'utf-8書出し変数の行末のタブは除外
.Cells(l_row, 1).Value = st_tsv
End If
'文字コードのTSVデータをタブで分解して文字列として各列にセット
.Cells(1, 1).Select 'A1セルを選択
Range(Selection, Selection.End(xlDown)).Select
Selection.TextToColumns Destination:=Range("A1"), DataType:=xlDelimited, TextQualifier:=1, Tab:=True, FieldInfo:=Array(Array(1, 2), Array(2, 2), Array(3, 2), _
Array(4, 2), Array(5, 2), Array(6, 2), Array(7, 2), Array(8, 2), Array(9, 2), Array(10, 2), Array(11, 2), Array(12, 2), Array(13, 2), Array(14, 2), Array(15, 2), Array(16, 2), _
Array(17, 2), Array(18, 2), Array(19, 2), Array(20, 2), Array(21, 2), Array(22, 2), Array(23, 2), Array(24, 2), Array(25, 2), Array(26, 2), Array(27, 2), Array(28, 2), _
Array(29, 2), Array(30, 2), Array(31, 2), Array(32, 2), Array(33, 2))
'書式設定
.Columns("A:AG").Font.Name = "MS ゴシック"
.Columns("A:AG").EntireColumn.AutoFit '列の幅を自動調整
.Columns("R:AG").ColumnWidth = 1 'utf8表示の列幅を再設定
.UsedRange.Select '全選択
End With
Application.ScreenUpdating = True '画面固定を解除
MsgBox (Timer - dbl_t) & " 秒"
End Sub
Shift-JIS編とUTF-8編での実行結果を比較する
この章では「処理速度」と「Shift-JISとUTF-8でそれぞれ文字コードで変換時の結果」を確認します。
処理速度
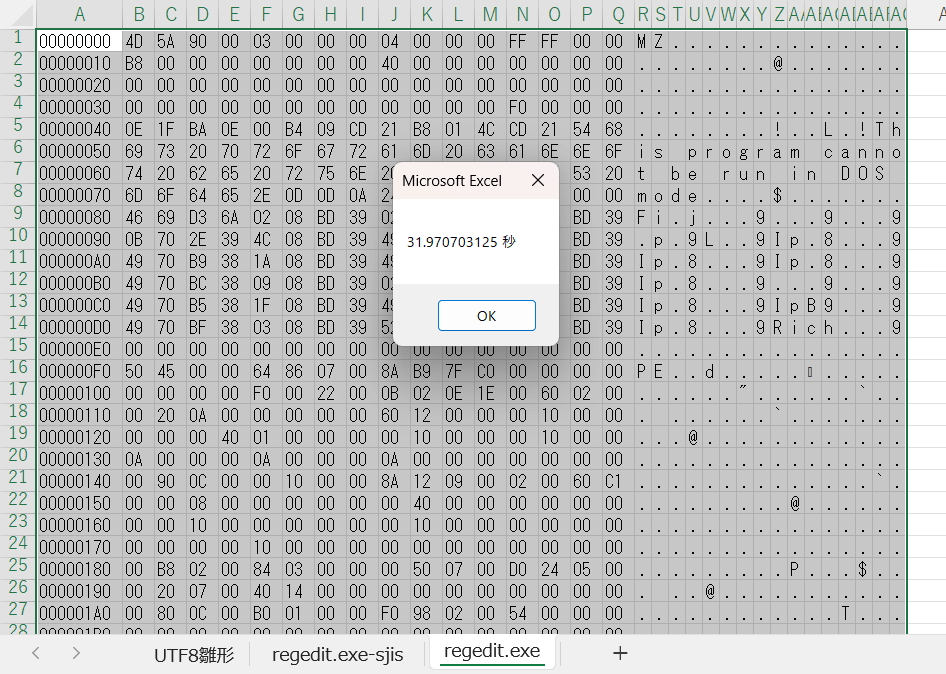
まずは処理速度ですが、同じ「regedit.exe」を読み込んだ時の処理時間は左図のように約32秒なりました。
Shift-JISの時は約21秒だったので11秒ほど遅くなっています。
※「regedit.exe」はc:\windows配下のファイルを直接読み込むのではなく、一度別なフォルダーにコピーしたものを使用しています。
処理時間が遅くなる理由としては次のような事が考えられます。
- 文字コード変換が組み込み関数ではなくユーザ関数
- 文字コードの数がShift-JISよりUTF-8の方がはるかに大きい。
文字コード変換した時の結果
Shift-JISでは1バイト文字に半角カナ領域(0xA1~0xDF)が割り当てられているのに対して、UTF-8では半角カナは3バイト文字の0xEFBDA8~0xEFBE9Dに割り当てられているので、半角カナ文字はめったに出現しません。
Shit-JISは長くて2バイト文字までなので、変換対象になる確率はUTF-8よりも高くなります。
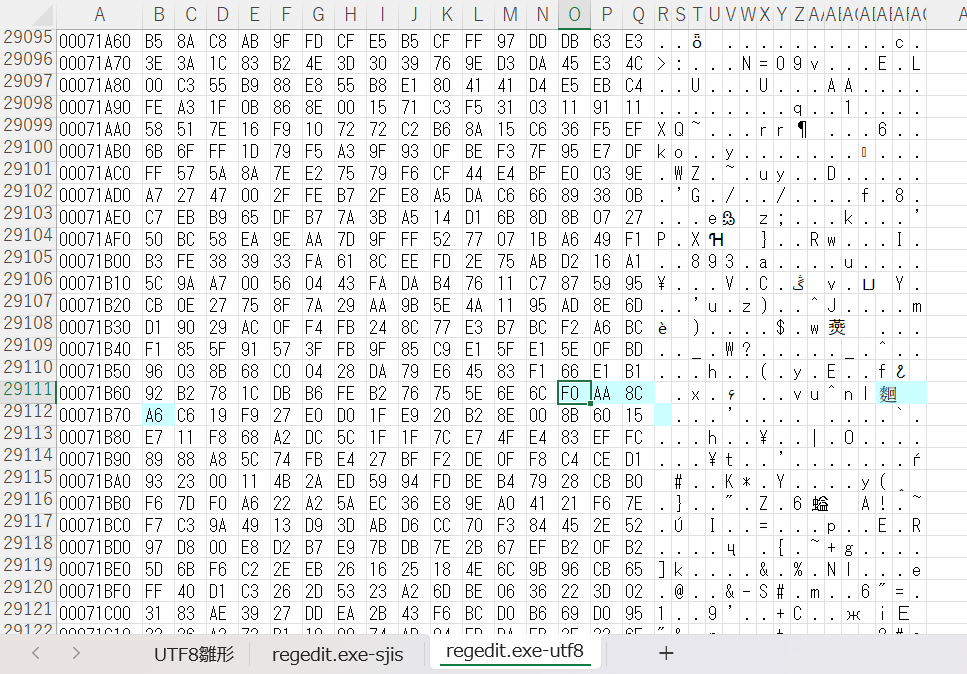
なお今回のregedit.exeの中に4バイト文字に該当する場合があるのか調べたところ、例えば下右図のように変換されるものがいくつかは存在していました。(だからと言って特に意味はないのですが…)

最後に
今回は前回からの2回に渡り「Excel VBAでバイナリーエディタを作る」をご紹介いたしました。
「そんなものを使うようなシーンがあるのか?」と言われると何とも言い難いところではありますが、今回主にお伝えしたかったのは次の2点です。
- バイナリーデータを文字コード変換する事の意味
- バイナリーファイルをExcelの中に収納できてしまう点
まず1点目ですが、バイナリーファイルはOSが処理し易い形に加工されているのですが、そのデータストリームの中にたまたま文字コードに当たるものが存在していたとして、それをコード変換している訳ですが正直2バイト文字以上の場合に意味のある情報は存在していないように思います。
ただ「何か情報が隠されていないか?を知りたい」という気持ちは分かりますので、この機能は外せないように思います。
次に2点目ですが、 Excelは本来は表計算だったり、グラフだったり、描画オブジェクトだったりのためのツールですが、テキスト情報としてバイナリーデータを収納してしまう点です。
この点を「悪意があるプログラム」に突かれてしまうと不測の事態を引き起こす可能性があり得ますので十分にご注意する必要がある認識です。
この場合、「ではコーディングの中で何を確認しなければならないか?」と思われると思うのですが、極論するとOpenステートメント構文の中に指定項目「Binary Access Writeが存在するか?」になるはずです。(この指定をすると書き込み操作のためにBinaryモードでファイルを開く事になります。)
ただそうであれば、「コーディングの中にBinary Access Writeが書かれているか?確認すれば良いのだ!」と思われるかもしれませんが、なかなかそうは簡単には「問屋が卸さない」のです。
次回はこの辺りの話をもう少し掘り下げて見たいと思います。
以上最後までご一読いただき誠にありがとうございました。